A review of the MachineConfig operator
- Posted on August 16, 2020
- kubernetes, kubeinit, cloud, okd
- By Carlos Camacho
The latest versions of OpenShift rely on operators to completely manage the cluster and OS state, this state includes for instance, configuration changes and OS upgrades. For example, to install additional packages or changing any configuration file to execute whatever task is required, the MachineConfig operator should be the one in charge of applying these changes.
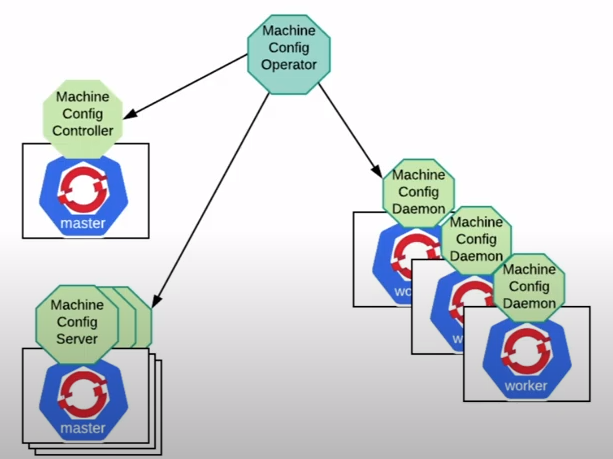
These configuration changes are executed by an instance of the ‘openshift-machine-config-operator’ pod, which after this new state is reached the updated nodes will be automatically restarted.
There are several mature and production-ready technologies allowing to automate and apply configuration changes to the underlying infrastructure nodes, like, Ansible, Helm, Puppet, Chef, and many others, yet, the MachineConfig operator force users to adopt this new method and pretty much discard any previously developed automation infrastructure.
The MachineConfig operator is more than installing packages and updating configuration files
I see this MachineConfig operator as a finite state machine where it’s represented a cluster-wide specific sequential logic to ensure that the cluster’s state is preserved and consistent. This notion has several and very powerful benefits, like making the cluster resilient to failures due to unfulfilled conditions in each of the sub-stages part of this finite state machine workflow.
For instance, let the following example show a practical and objective application of the benefits of this approach.
We assume the following architecture reference:
- 3 master nodes.
- 1 worker node.
- The master nodes are not schedulable.
This is a quite simple multi-master deployment with a single worker node
for development purposes, before the cluster was deployed the
master nodes were set as “mastersSchedulable: False” by running
"sed -i 's/mastersSchedulable: true/mastersSchedulable: False/' install_dir/manifests/cluster-scheduler-02-config.yml".
Now, after deploying the cluster and executing a configuration change in the worker node it will
fail, and let investigate why.
The following yaml file will be applied, which it’s content is correct and it should work out of the box:
cat << EOF > ~/99_kubeinit_extra_config_worker.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
creationTimestamp: null
labels:
machineconfiguration.openshift.io/role: worker
name: 99-kubeinit-extra-config-worker
spec:
osImageURL: ''
config:
ignition:
config:
replace:
verification: {}
security:
tls: {}
timeouts: {}
version: 2.2.0
networkd: {}
passwd: {}
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvdXNyL2Jpbi9iYXNoCnNldCAteAptYWluKCkgewpzdWRvIHJwbS1vc3RyZWUgaW5zdGFsbCBwb2xpY3ljb3JldXRpbHMtcHl0aG9uLXV0aWxzCnN1ZG8gc2VkIC1pICdzL2VuZm9yY2luZy9kaXNhYmxlZC9nJyAvZXRjL3NlbGludXgvY29uZmlnIC9ldGMvc2VsaW51eC9jb25maWcKfQptYWluCg==
verification: {}
filesystem: root
mode: 0755
path: /usr/local/bin/kubeinit_kubevirt_extra_config_script
EOF
oc apply -f ~/99_kubeinit_extra_config_worker.yaml
The defined MachineConfig object will create a file in
/usr/local/bin/kubeinit_kubevirt_extra_config_script that once executed it will
install a package and disable SElinux in the worker nodes.
Now, let’s check the state of the worker machine config pool.
oc get machineconfigpool/worker
This is the result:
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
worker rendered-worker-a9.. False True True 1 0 0 1 12h
Now it is possible to depict that the operator state is degraded and there is not much more information about it. Let’s get the status of the machine-config pods.
kubectl get pod -o wide --all-namespaces | grep machine-config
It is possible to see that all pods are running without issues.
openshift-machine-config-operator etcd-quorum-guard-7bb76959df-5bj7g 1/1 Running 0 11h 10.0.0.2 okd-master-02 <none> <none>
openshift-machine-config-operator etcd-quorum-guard-7bb76959df-jdtbv 1/1 Running 0 11h 10.0.0.3 okd-master-03 <none> <none>
openshift-machine-config-operator etcd-quorum-guard-7bb76959df-sndb2 1/1 Running 0 11h 10.0.0.1 okd-master-01 <none> <none>
openshift-machine-config-operator machine-config-controller-7cbb584655-bfjmh 1/1 Running 0 11h 10.100.0.20 okd-master-01 <none> <none>
openshift-machine-config-operator machine-config-daemon-ctczg 2/2 Running 0 12h 10.0.0.3 okd-master-03 <none> <none>
openshift-machine-config-operator machine-config-daemon-m82gz 2/2 Running 0 12h 10.0.0.2 okd-master-02 <none> <none>
openshift-machine-config-operator machine-config-daemon-qfc82 2/2 Running 0 12h 10.0.0.1 okd-master-01 <none> <none>
openshift-machine-config-operator machine-config-daemon-vwh4d 2/2 Running 0 11h 10.0.0.4 okd-worker-01 <none> <none>
openshift-machine-config-operator machine-config-operator-c98bb964d-5vnww 1/1 Running 0 11h 10.100.0.21 okd-master-01 <none> <none>
openshift-machine-config-operator machine-config-server-g75x5 1/1 Running 0 12h 10.0.0.2 okd-master-02 <none> <none>
openshift-machine-config-operator machine-config-server-kpwqb 1/1 Running 0 12h 10.0.0.3 okd-master-03 <none> <none>
openshift-machine-config-operator machine-config-server-n9q2r 1/1 Running 0 12h 10.0.0.1 okd-master-01 <none> <none>
Let’s check the logs of the machine-config-daemon pod in the worker node. This pod has two containers, machine-config-daemon, and oauth-proxy.
kubectl logs -f machine-config-daemon-vwh4d -n openshift-machine-config-operator -c machine-config-daemon
Now, it is possible to see the actual error in the container execution:
I0816 06:58:42.985762 3240 update.go:283] Checking Reconcilable for config rendered-worker-a9681850fe39078ea0f42bd017922eb7 to rendered-worker-7131e04f110c489a0ad171e719cedc24
I0816 06:58:43.849830 3240 update.go:1403] Starting update from rendered-worker-a9681850fe39078ea0f42bd017922eb7 to rendered-worker-7131e04f110c489a0ad171e719cedc24: &{osUpdate:false kargs:false fips:false passwd:false files:true units:false kernelType:false}
I0816 06:58:43.852961 3240 update.go:1403] Update prepared; beginning drain
E0816 06:58:43.911711 3240 daemon.go:336] WARNING: ignoring DaemonSet-managed Pods: openshift-cluster-node-tuning-operator/tuned-48g5s, openshift-dns/dns-default-h2lt5, openshift-image-registry/node-ca-9z9zt, openshift-machine-config-operator/machine-config-daemon-vwh4d, openshift-monitoring/node-exporter-m5p2n, openshift-multus/multus-lnsng, openshift-sdn/ovs-5xzqs, openshift-sdn/sdn-vplps
.
.
.
I0816 06:58:43.918261 3240 daemon.go:336] evicting pod openshift-ingress/router-default-796df5847b-9hxzx
E0816 06:58:43.928176 3240 daemon.go:336] error when evicting pod "router-default-796df5847b-9hxzx" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
I0816 07:08:44.981198 3240 update.go:172] Draining failed with: error when evicting pod "router-default-796df5847b-9hxzx": global timeout reached: 1m30s, retrying
E0816 07:08:44.981273 3240 writer.go:135] Marking Degraded due to: failed to drain node (5 tries): timed out waiting for the condition: error when evicting pod "router-default-796df5847b-9hxzx": global timeout reached: 1m30s
The log shows that the machine config operator failed to drain the worker node before applying the
configuration and executing the restart, as the router-default pod was not able to be
rescheduled in another node. Not being able to schedule again this pod
violates the pod's disruption budget, thus, the operator is now degraded.
Let’s check the router-default pod status:
kubectl get pod -o wide --all-namespaces | grep "router-default"
It is possible to see that the pod is pending to be scheduled.
openshift-ingress router-default-796df5847b-9hxzx 1/1 Running 0 12h 10.0.0.4 okd-worker-01 <none> <none>
openshift-ingress router-default-796df5847b-h8bm4 0/1 Pending 0 12h <none> <none> <none> <none>
Let’s check it’s status:
oc describe pod router-default-796df5847b-h8bm4 -n openshift-ingress
Now, it is possible to confirm that the pod is Pending as there is not any available node to schedule it back again.
Name: router-default-796df5847b-h8bm4
Namespace: openshift-ingress
.
.
.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/4 nodes are available: 1 node(s) were unschedulable, 3 node(s) didn't match node selector.
We check the nodes status
oc get nodes
Again, it is possible to see that the MachineConfig operator tried to drain the node but it failed when rescheduling its pods.
NAME STATUS ROLES AGE VERSION
okd-master-01 Ready master 12h v1.18.3
okd-master-02 Ready master 12h v1.18.3
okd-master-03 Ready master 12h v1.18.3
okd-worker-01 Ready,SchedulingDisabled worker 12h v1.18.3
Why did this happen?
Master nodes are not schedulable to handle workloads, this was configured when the cluster was deployed. So pretty much the operator didn’t have enough room to reschedule the pods in other nodes.
The benefits of this approach (using the MachineConfig operator) are uncountable as the operator is smart enough to avoid services breaking when it finds that a configuration change is not able to get the system back to a consistent state.

But, not everything is as perfect as it sounds…
Ignition files are used to apply these configuration changes and it’s json representation is not human-readable at all, for this we use Fedora CoreOS Configuration (FCC) files in YAML format, then internally these yaml files are converted into an Ignition (JSON) file by the Fedora CoreOS Config Transpiler, which is a tool that produces a JSON Ignition file from the YAML FCC file.
There is a huge limitation in the resources that can be defined, it is only supported storage, system.d services, and users, so, for executing anything the user will have to render a script that must be called once by a systemd service after the node restarts. This, after using for many many years technologies like Ansible, Puppet, or Chef, it looks like a hacky and dirty approach for users to apply their custom configurations.
Another thing, debugging, if there is a problem with your MachineConfig object you might see only this degraded state, forcing you to dig into the containers logs and hopefully find the source of any issue you might have.
I believe there is a lot of room for improvements in the MachineConfig operator, I would love to see an Ansible interface to be able to plug-in my configuration changes by the openshift-machine-config-operator pod. Also, it was showed that the operator improves the system’s resiliency by impeding that a configuration change breaks what we defined as a cluster’s consistent state.
Responses
Want to leave a comment? Visit this post's issue page on GitHub (you'll need a GitHub account. What? Like you already don't have one?!).