Advanced Deployment with Red Hat OpenShift - Retrospective
- Posted on July 02, 2019
- cloud, openshift, engineering
- By Carlos Camacho
I had the opportunity to attend last week to a training session in the office about Advanced Deployment with Red Hat OpenShift. The course in general covers installing Red Hat OpenShift Container Platform in an HA environment or without an internet connection.

Other topics include networking and security configuration, and management skills using Red Hat OpenShift Container Platform. In theory, after completing the course, you should be able to:
- Describe and install OpenShift in an HA environment.
- Describe and configure OpenShift Machines.
- Describe and configure networking including creating network policies to secure applications.
- Describe and configure the OpenShift Scheduler.
- Protect the platform using quotas and limits.
- Describe and install OpenShift without an internet connection (disconnected install).
As usual, there is some previous knowledge about the technology presented in this course you should have, among others you should have some:
- Understanding of networking and concepts such as routing and software-defined networking (SDN)
- Understanding of containers and virtualization
- Basic understanding of development life cycle and developer workflow
- Ability to read and modify code
The course is comprised of 8 modules covering:
- Introduction to Course and Learning Environment.
- Learn about the Advanced Deployment with Red Hat OpenShift course.
- Understand the prerequisites, training environment, and system designations used during the lab procedures.
- Learn tips for successfully completing the labs.
- Understand course resources.
Disconnected Install
- Learn what a disconnected install is and about the architectures for disconnected environments.
- Learn about the advanced installed and the reference configuration implemented with Ansible Playbooks.
- Review the software components required for a disconnected install, including Red Hat OpenShift Container Platform installation software, Red Hat OpenShift Container Platform images, a source code repository, and a development artifact repository.
- Learn how to import images from preloaded Docker storage or a local repository.
- Perform an installation of Red Hat OpenShift Container Platform, including importing other images such as Nexus and deploying other infrastructure like the source code repository.
OpenShift 4 Installation
- Review the many components of the OpenShift architecture.
- Use OpenShift installer to deploy an HA OpenShift cluster.
- Understand how application HA is achieved with the replication controller and the scheduler.
- Learn about container log aggregation and metrics collection.
- Use diagnostics tools in server and client environments.
Machine Management
- Review how OpenShift manages underlying infrastructure
- Change MachineSet and Machine Configuration
- Add nodes by scaling MachineSets
- Understand and configure the Cluster Autoscaler
Networking
- Review networking goals and software-defined networking (SDN).
- Review packet-flow scenarios and learn about traffic inside an OpenShift cluster.
- Learn about local traffic in a cluster and how OpenShift controls access between different OpenShift namespaces and projects.
- Learn how pods connect to external hosts and how IPTables controls access to networks outside the SDN cluster.
- Study how pods communicate across a cluster and about traffic inside a cluster.
- Learn about pod IP allocation and network isolation.
- Configure SDN and set up external access.
- Study project network management and setting secure network policies.
- Learn about the seven common use cases for NetworkPolicy.
- Learn about OpenShift internal DNS.
- Learn about external access, including load balancing in SDN and establishing a tunnel in ramp mode.
- Understand how OpenShift masters also serve as an internal domain name service (DNS).
Network Policy
- Learn about NetworkPolicy
- Configure NetworkPolicy objects in the cluster
- Protect a complex application using NetworkPolicy
Managing Compute Resources
- Learn what compute resources are and about requesting, allocating, and consuming them.
- Learn about compute requests, CPU limits, and memory limits.
- Learn about quality of service (QoS) tiers.
- Create, edit, and delete project resource limits.
- Learn how limit ranges enumerate and specify project compute resource constraints for pods, containers, images, and image streams.
- Learn about container limits and image limits.
- Learn how to use quotas and limit ranges to limit the number of objects or amount of compute resources that are used in a project.
- Understand which resources can be managed with quotas.
- Learn how BestEffort, NotBestEffort, Terminating, and NotTerminating quota scopes restricts pod resources.
- Understand how quotas are enforced and how to set quotas across multiple projects.
- Learn about overcommitting CPU and memory and how to configure overcommitting.
General comments
I really liked the course, It wasn’t much advanced in general but it was a very good approach to “the actual thing” people are doing when deploying the technology for production ready environment.
It’s an operators course IMHO and not a developers course, I missed to have an actual view about where is the code, how is organized an how can we contribute with the Kubernetes/OpenShift community.
It has a very nice 8 hours exam xD xD :/ ;( at the very end as a proof that you understood what you did there, I think I did it OK but still, I’m waiting for the course test results.
Even though, I tried to dig into the code and understand better the integration with the python-kubernetes client and gladly created an issue report with its corresponding PR to fix it :)
This will be now a brief history about what I hacked in the cluster when doing the course.
Hacking the environment
Let’s start with the research question!
- How the replication controller manage a massive pods kill?
- Did it recover fast?
- Did it recover at all?
Let’s create a simple web application using 500 pods.
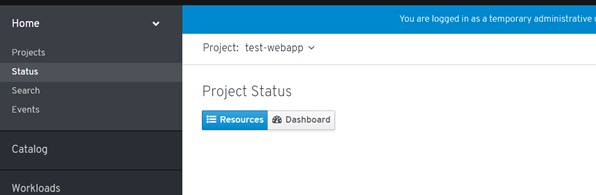
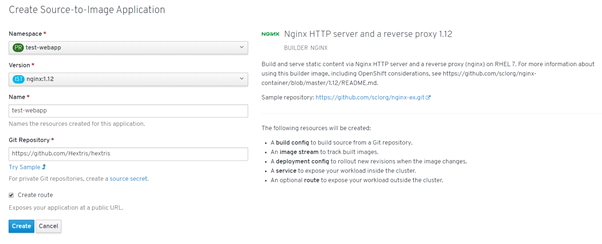
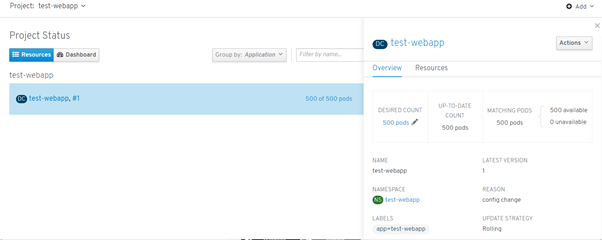
I have created a simple script using the Python Kubernetes client to demonstrate the cluster behavior
The Python script is a simple application using two threads in order to measure the number of available and unavailable pods for the application at the same time we kill some pods based in a Poisson distribution.
Let’s see how the cluster behaves when killing the pods number from the test-webapp namespace
[ccamacho@localhost mocoloco]$ python script.py
Buum!
The Python Kubernetes client failed, allowing me to create a GitHub Issue report and a Pull request with its corresponding fix.
First error within the Kubernetes python client:
test-webapp-1-zv6jr Running 10.129.2.168
Traceback (most recent call last):
File "watch.py", line 75, in <module>
for event in stream:
File "/usr/lib/python2.7/site-packages/kubernetes/watch/watch.py", line 134, in stream
for line in iter_resp_lines(resp):
File "/usr/lib/python2.7/site-packages/kubernetes/watch/watch.py", line 47, in iter_resp_lines
for seg in resp.read_chunked(decode_content=False):
AttributeError: 'HTTPResponse' object has no attribute 'read_chunked'
The execution
After hacking around a bit with the client’s methods this is the result
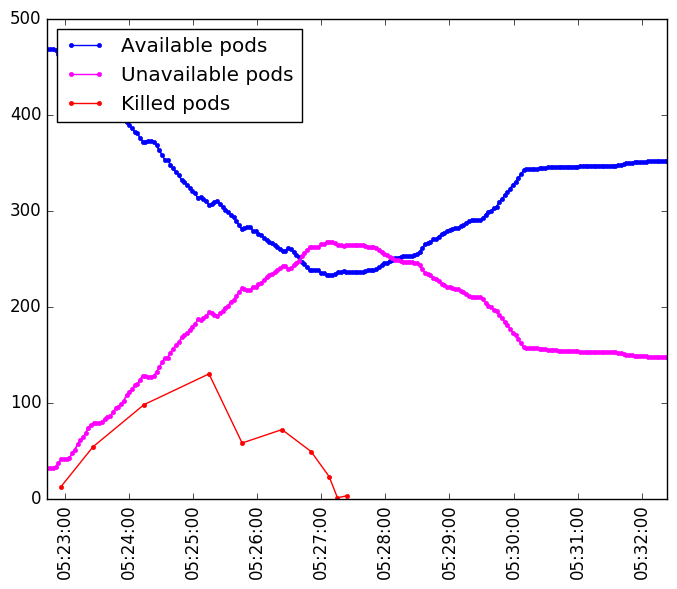
It seems that even if the pods creation is fast enough it takes some time to fully recover.
Here is the whole script if you are insterested:
import matplotlib
matplotlib.use('Agg')
import random
import time
from scipy.stats import poisson
import matplotlib.pyplot as plt
import matplotlib.dates as md
from kubernetes import client, config
from kubernetes.client.rest import ApiException
import threading
import datetime
global_available=[]
global_unavailable=[]
global_kill=[]
t1_stop = threading.Event()
t2_stop = threading.Event()
def delete_pod(name, namespace):
core_v1 = client.CoreV1Api()
delete_options = client.V1DeleteOptions()
try:
api_response = core_v1.delete_namespaced_pod(
name=name,
namespace=namespace,
body=delete_options)
except ApiException as e:
print("Exception when calling CoreV1Api->delete_namespaced_pod: %s\n" % e)
def get_pods(namespace=''):
api_instance = client.CoreV1Api()
try:
if namespace == '':
api_response = api_instance.list_pod_for_all_namespaces()
else:
api_response = api_instance.list_namespaced_pod(namespace, field_selector='status.phase=Running')
return api_response
except ApiException as e:
print("Exception when calling CoreV1Api->list_pod_for_all_namespaces: %s\n" % e)
def get_event(namespace, stop):
while not stop.is_set():
config.load_kube_config()
configuration = client.Configuration()
configuration.assert_hostname = False
api_client = client.api_client.ApiClient(configuration=configuration)
dat = datetime.datetime.now()
api_instance = client.AppsV1beta1Api()
api_response = api_instance.read_namespaced_deployment_status('example', namespace)
global_available.append((dat,api_response.status.available_replicas))
global_unavailable.append((dat,api_response.status.unavailable_replicas))
time.sleep(2)
t2_stop.set()
print("Ending live monitor")
def run_histogram(namespace, stop):
# random numbers from poisson distribution
n = 500
a = 0
data_poisson = poisson.rvs(mu=10, size=n, loc=a)
counts, bins, bars = plt.hist(data_poisson)
plt.close()
config.load_kube_config()
configuration = client.Configuration()
configuration.assert_hostname = False
api_client = client.api_client.ApiClient(configuration=configuration)
for experiment in counts:
pod_list = get_pods(namespace=namespace)
aux_li = []
for fil in pod_list.items:
if fil.status.phase == "Running":
aux_li.append(fil)
pod_list = aux_li
# From the Running pods I randomly choose those to die
# based on the histogram length
to_be_killed = random.sample(pod_list, int(experiment))
for pod in to_be_killed:
delete_pod(pod.metadata.name,pod.metadata.namespace)
print("To be killed: "+str(experiment))
global_kill.append((datetime.datetime.now(), int(experiment)))
print(datetime.datetime.now())
print("Ending histogram execution")
time.sleep(300)
t1_stop.set()
def plot_graph():
plt.style.use('classic')
ax=plt.gca()
ax.xaxis_date()
xfmt = md.DateFormatter('%H:%M:%S')
ax.xaxis.set_major_formatter(xfmt)
x_available = [x[0] for x in global_available]
y_available = [x[1] for x in global_available]
plt.plot(x_available,y_available, color='blue')
plt.plot(x_available,y_available, color='blue',marker='o',label='Available pods')
x_unavailable = [x[0] for x in global_unavailable]
y_unavailable = [x[1] for x in global_unavailable]
plt.plot(x_unavailable,y_unavailable, color='magenta')
plt.plot(x_unavailable,y_unavailable, color='magenta',marker='o',label='Unavailable pods')
x_kill = [x[0] for x in global_kill]
y_kill = [x[1] for x in global_kill]
plt.plot(x_kill,y_kill,color='red',marker='o',label='Killed pods')
plt.legend(loc='upper left')
plt.savefig('foo.png', bbox_inches='tight')
plt.close()
if __name__ == "__main__":
namespace = "test-webapp"
try:
t1 = threading.Thread(target=get_event, args=(namespace, t1_stop))
t1.start()
t2 = threading.Thread(target=run_histogram, args=(namespace, t2_stop))
t2.start()
except:
print "Error: unable to start thread"
while not t2_stop.is_set():
pass
print ("Ended all threads")
plot_graph()
Responses
Want to leave a comment? Visit this post's issue page on GitHub (you'll need a GitHub account. What? Like you already don't have one?!).